DeepSeek-V4上线:使用华为芯片训练,性能比Gemini差3-6个月,价格优势明显
热点
2026-04-24
菜科探索
+

简介:更具产业里程碑意义的是,DeepSeek-V4从模型设计之初就深度适配国产算力,在华为昇腾芯片生态实测跑通,成为全球首个在国产算力底座上完成训练与推理的万亿参数级模型,打破对海外芯片与框架的长期依赖。
D…
【菜科解读】

出品|搜狐科技
作者|郑松毅、常博硕
编辑|杨锦
DeepSeek V4,来了!
OpenAI GPT 5.5 前脚刚发布,DeepSeek就亮出了“真家伙”。
就在刚刚,DeepSeek-V4的预览版本正式上线并同步开源。
据官方介绍,DeepSeek-V4拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。
模型按大小分为两个版本:

更具产业里程碑意义的是,DeepSeek-V4 从模型设计之初就深度适配国产算力,在华为昇腾芯片生态实测跑通,成为全球首个在国产算力底座上完成训练与推理的万亿参数级模型,打破对海外芯片与框架的长期依赖。
性能比肩顶级闭源模型,价格比Claude便宜21倍
官方实测数据显示,DeepSeek-V4-Pro性能比肩顶级闭源模型。
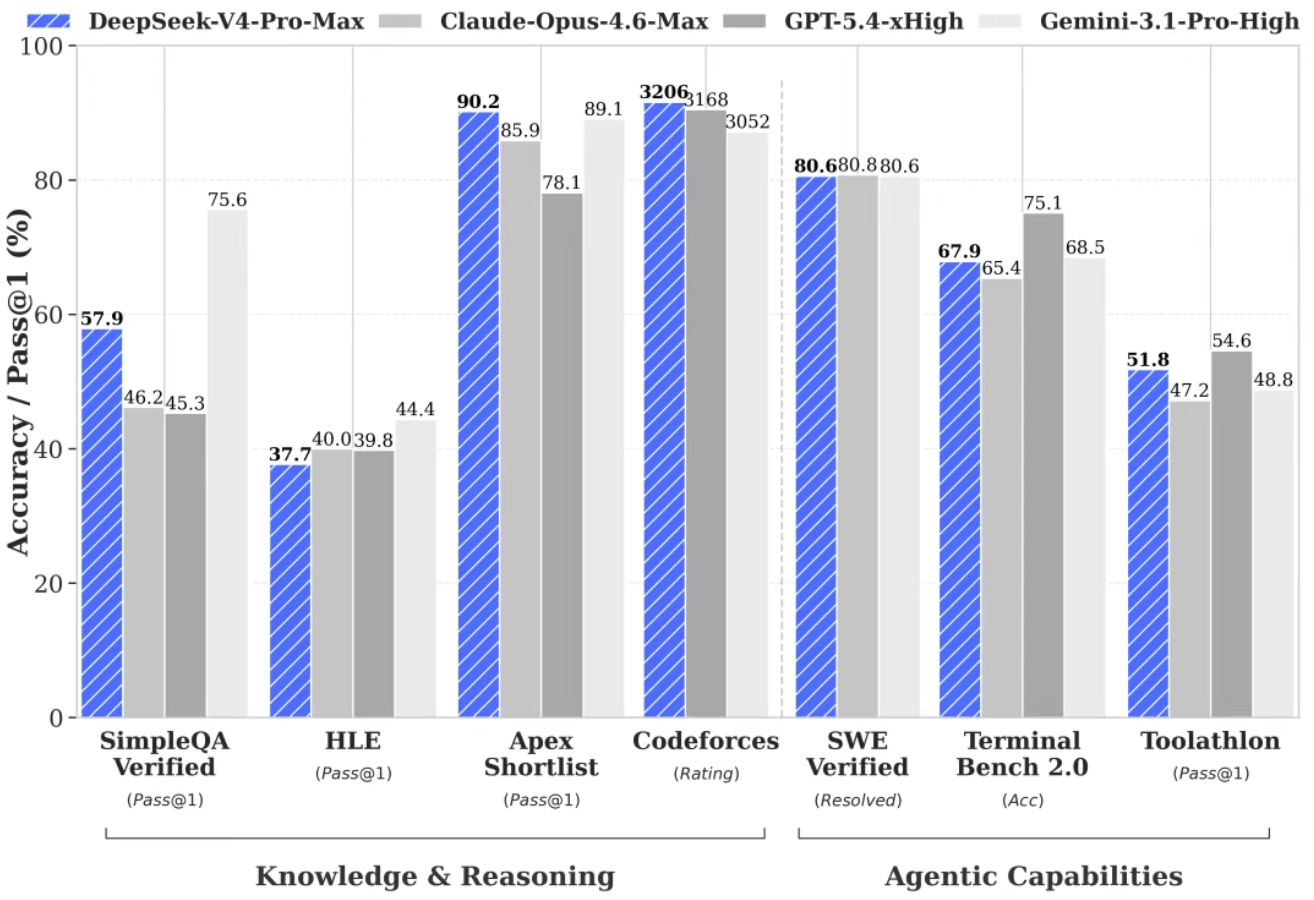
Agent(智能体)能力方面,相比前代模型,DeepSeek-V4-Pro的能力显著增强。
在 Agentic Coding 评测中,V4-Pro 已达到当前开源模型最佳水平,并在其他 Agent 相关评测中同样表现优异。
DeepSeek介绍,目前 DeepSeek-V4 已成为公司内部员工使用的 Agentic Coding 模型,据评测反馈使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与Opus 4.6 思考模式存在一定差距。
DeepSeek给出的结论相对克制。
在知识与推理任务上,其性能已经超过主流开源模型,并接近Gemini等闭源系统,但仍存在约3到6个月差距。
在 agent和代码任务上,其表现接近甚至部分超过Claude Sonnet。
此外,在数学、STEM、竞赛型代码的测评中,DeepSeek-V4-Pro超越当前所有已公开评测的开源模型(包括月之暗面的K2.6 Thinking、智谱GLM-5.1 Thinking等),取得了比肩世界顶级闭源模型的优异成绩。
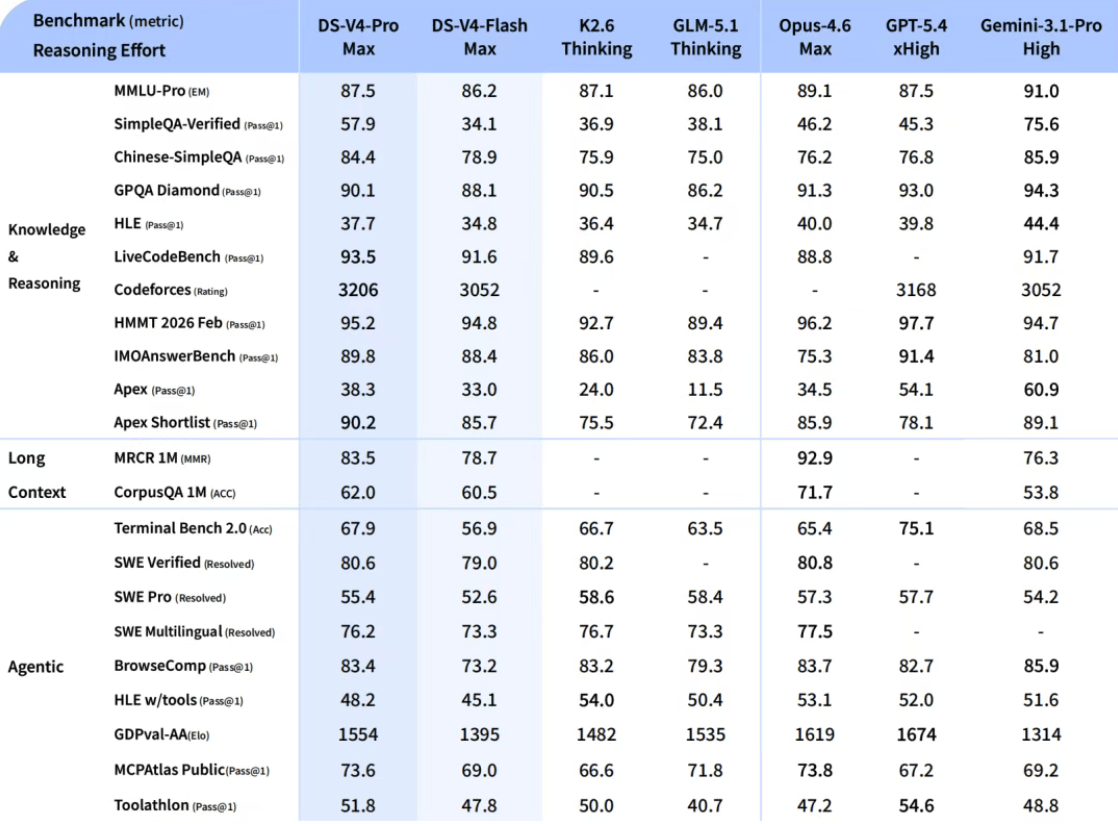
相较之下,DeepSeek-V4-Flash主打性价比,能够提供更加快捷、经济的 API 服务。
在 Agent 测评中,DeepSeek-V4-Flash 在简单任务上与 DeepSeek-V4-Pro 旗鼓相当,但在高难度任务上仍有差距。
据悉,V4-Pro 与 V4-Flash 最大上下文长度为 1M,均同时支持非思考模式与思考模式,其中思考模式支持 reasoning_effort 参数设置思考强度(high/max)。
对于复杂的 Agent 场景建议使用思考模式,并设置强度为 max。
使用价格如下:
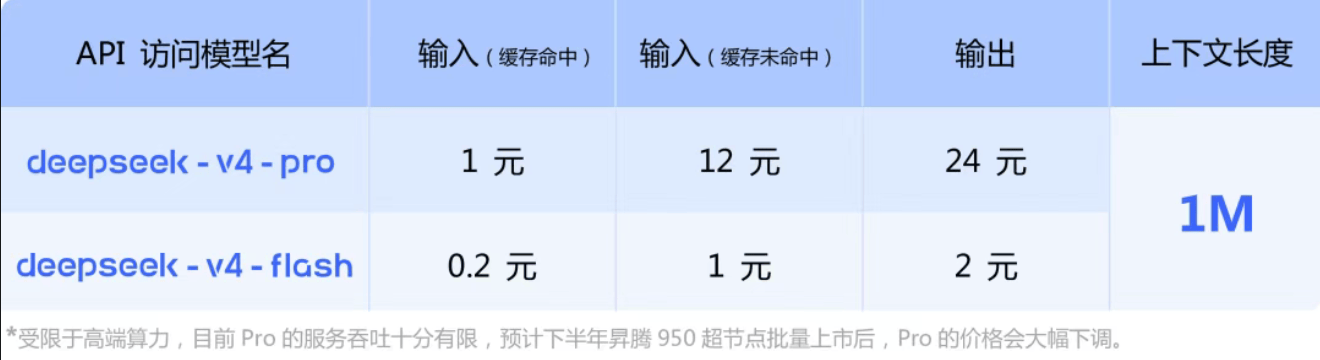
DeepSeek表示,“受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。
”
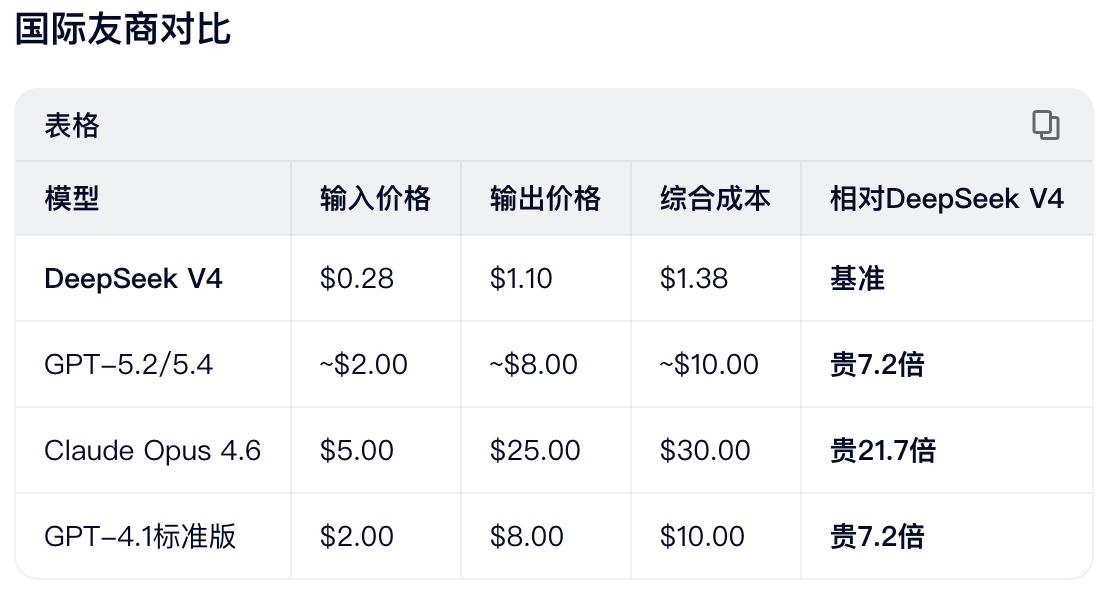
再看看国际友商价格对比,可见DeepSeek的实惠:
混合架构解决工程落地痛点,全面适配国产算力
大模型处理超长文本的最大痛点,从来不是 “能不能装下”,而是跑不动、记不住、算不起。
随着传统注意力机制呈平方级复杂度攀升,百万Token场景下显存与算力直接 “爆炸”,几乎无法工程落地。
DeepSeek-V4 的发布,标志着大模型正式走出 “参数竞赛”,进入效率优先下一代赛道。
从一口气审计全量代码库、一次性解析千页合同,到全程记住长时间会议、串联多轮复杂智能体任务,V4让AI 真正具备“完整理解、长期记忆、深度推理”的能力,同时把使用成本大幅下拉。
这一切得益于DeepSeek业内首创“CSA (压缩稀疏注意力) + HCA (重度压缩注意力)”的混合架构。
用一套“分级压缩 + 分级检索”思路,把效率拉到极致。
这一新方法显著减少了计算复杂度,提升了长上下文处理的效率。

具体来看,CSA像给长文本做重点精读。
先把每 4 个Token压缩成一个信息块,再用稀疏检索只挑最相关的内容,既保留中段细节,又大幅削减计算量,兼顾精准与效率。
HCA像给长文本做大纲速读,把海量信息浓缩成框架级块,专门负责全局逻辑。
官方数据显示:1M Token场景下,V4-Pro 仅需 V3.2 的 27% 推理算力、10% KV 缓存;
Flash 版更是低至 10% 算力、7% 缓存。
除了混合注意力,V4 还带来三项关键技术革新,构成完整效率革命:
mHC 流形约束超连接:升级传统残差连接,把信号传播约束在稳定流形上,深层不衰减、训练不炸数值。
Muon 优化器:替代传统 AdamW,收敛更快、训练更稳,完美适配 MoE 大模型与低精度训练,解决大批次长上下文训练的抖动难题。
全链路工程优化:专家并行细粒度通信重叠、TileLang 内核开发、FP4 量化感知训练、异构 KV 缓存管理,从计算、通信、存储全方位降本提速,推理加速最高近2倍。
最受大家关心的,是V4这次是否成功全面适配国产算力?
报告指出,DeepSeek-V4在英伟达 GPU 与华为昇腾 NPU 两大硬件平台上,对细粒度 EP 优化方案完成了全面验证。
相较于性能优异的非融合基线方案,该方案在通用推理负载场景下可实现1.50~1.73 倍的加速比。
有业内观点指出,这代表已经完成华为昇腾平台的适配和实测落地。
但目前对外开源的只有英伟达GPU版本,昇腾适配代码未开源,属于闭源适配优化。
值得一提的是,寒武纪在软硬一体生态中,已经完成基于 vLLM 推理框架完成对 285B DeepSeek-V4-flash 和 1.6T DeepSeek-V4-pro 的适配,适配代码已开源到 GitHub 社区。
剩下的,就等DeepSeek-V4的实用表现了。
还有DeepSeek的首轮融资最终花落谁家,也还是个谜题。
“不诱于誉,不恐于诽,率道而行,端然正己。
”
DeepSeek官方在文章最后表示,他们将始终秉持长期主义的原则理念,在尝试与思考中踏实前行,努力向实现 AGI 的目标不断靠近。
淘宝推“龙虾版”生意管家,电商AI竞争转向Agent团队
(了解详情) 3月底,淘宝天猫将上线一款名为“龙虾版”的生意管家。这个命名意在强调其多触手的覆盖能力,平台希望这套工具不再局限于单个环节,而是成为一个能够渗透店铺经营各个角落的全链路AI系统。
根据淘天集团在2026天猫TOP TALK上的披露,这套工具的核心是为商家提供一支由AI Agent组成的7乘24小时团队。
它整合了数据分析、设计、广告投放和智能导购四个核心角色,相当于将一个“店长加超级专家加多名员工”的配置打包成了一个数字工作台。
比如通过TMIC深度融合大模型,让品牌定制专属Agent辅助研发,号称效率能提升20倍。
淘宝此举背后,是电商AI赛道的竞争逻辑正在发生质变。
京东同时还推出了行业首个承诺100%赔付的“稳赚计划”,试图解决商家对广告投放ROI不确定的焦虑。
与此同时,拼多多和抖音也在各自的商家后台强化AI能力的渗透。
拼多多商家版主打多店铺管理和极速响应,抖音的“抖店”则深度绑定直播与内容场景,强调从流量到转化的闭环。
与淘宝此次推出的“全链路Agent团队”相比,各家侧重点有所不同:京东倾向于以免费工具降低商家进入门槛,而淘宝则更强调AI作为“数字员工”的深度协同能力。
当AI工具从“有没有”变成“好不好用”,甚至演变为“能不能独立干活”时,商家的选择标准也在发生变化。
一个值得关注的趋势是,2026年的电商AI不再仅仅是解决人力不足的问题,而是开始介入决策环节,比如辅助选品、自动优化广告出价、甚至自主处理售后协商。
那么,当淘宝试图用“龙虾”的多触手覆盖全链路,京东用免费策略和ROI保底拉拢中小商家,拼多多和抖音凭借各自的流量生态构建壁垒时,商家究竟是该选择一套大而全的“全能管家”,还是组合使用多个垂直领域的“单点专家”? 这场由AI Agent引发的效率竞赛,最终会不会导致电商运营的门槛不降反升,让没有能力驾驭复杂工具的中小商家再次掉队? 这里认真推荐你报名: 黑马·AI星球Agent实战营 黑马·AI星球Agent实战营,系国内⾸个基于“全链路业务拆解+Agent搭建实战”的企业级Agent实战营,3天闭关+90天陪跑,让你带走: 1、一套完整的企业级Agent构建方法论 2、一个基于真实业务场景的可运行Agent Demo 3、一份量身定制的落地推进计划 4、在线陪跑与生态资源对接支持 让AI真正落地变现! 扫码咨询报名 活动详情如下 黑马精选
谷歌新论文把内存股价干崩了!KV cache压缩6倍,“谷歌的DeepSeek时刻”
广告 谷歌新论文把内存股价干崩了!KV cache压缩6倍,“谷歌的DeepSeek时刻” 10:00 广告 广告 广告 了解详情 > 会员跳广告 首月9.9元 秒后跳过广告 开通搜狐视频黄金会员,尊享更高品质体验! 1080P及以上画质仅为黄金会员专享> 开通/续费会员 抱歉,您观看的视频加载失败 请检查网络连接后重试,有话要说?请点击 我要反馈>> 正在切换清晰度... 播放 按esc可退出全屏模式 00:00 00:00 00:13 广告 只看TA 高清 倍速 剧集 字幕 下拉浏览更多 5X进行中 炫彩HDRVIP尊享HDR视觉盛宴 超清 720P 高清 540P 2.0x 1.5x 1.25x 1.0x 0.8x 50 哎呀,什么都没识别到 反馈 循环播放 跳过片头片尾 画面色彩调整 AI明星识别 视频截取 跳过片头片尾 是 | 否 色彩调整 亮度 标准 饱和度 100 对比度 100 恢复默认设置 关闭 复制全部log 梦晨 发自 凹非寺 量子位 | 公众号 QbitAI 学术会议ICLR,居然和美光和西部数据大跌扯上关系了? 两家存储芯片巨头股价大跌,没有财报暴雷,没有供应链断裂,只是谷歌展示了一篇即将在ICLR 2026正式亮相的论文。谷歌研究院推出TurboQuant压缩算法,把AI推理过程中最吃内存的KV cache压缩至少6倍,精度零损失。
市场的解读简单粗暴,长上下文AI推理以后不需要那么多内存了,利空内存。
网友纷纷表示,这不就是美剧《硅谷》里的Pied Paper? Pied Piper是2014年开播的HBO经典美剧《硅谷》里的虚构创业公司,核心技术就是一种“近乎无损的极限压缩算法”。
2026年,类似的算法在现实世界居然成真了。
KVCache量化到3 bit 要理解TurboQuant为什么重要,先得理解它解决的是什么问题。
AI大模型推理时处理过的信息会临时存在KV Cache,方便后续快速调用,不用每次从头算起。
问题是随着上下文窗口越来越长,内存消耗急剧膨胀。
KV cache正在成为AI推理的核心瓶颈之一。
传统的解决思路是向量量化,把高精度数据压成低精度表示。
但尴尬的是,大部分量化方法本身也需要存储额外的“量化常数”,每个数字要多占1到2个bit。
TurboQuant用两个改动把这个额外开销干到了零。
PolarQuant(极坐标量化): 不用传统的X、Y、Z坐标描述数据,转而用极坐标”距离+角度”。
谷歌团队发现,转换后角度的分布非常集中且可预测,根本不需要额外存储归一化常数。
就像把“往东走3个路口,往北走4个路口”压缩成”朝37度方向走5个路口”。
信息量不变,描述更紧凑,还省掉了坐标系本身的开销。
QJL(量化JL变换): 把高维数据投影后压缩成+1或-1的符号位,完全不需要额外内存。
TurboQuant用它来消除PolarQuant压缩后残留的微小误差。
两者组合后PolarQuant先用大部分bit容量捕捉数据的主要信息,QJL再用1个bit做残差修正。
最终实现3-bit量化,无需任何训练或微调,精度零损失。
8倍加速,Benchmark全线拉满 谷歌团队在Gemma和Mistral等开源模型上,跑了主流长上下文基准测试,覆盖问答、代码生成、摘要等多种任务。
在“大海捞针”任务上,TurboQuant在所有测试中拿下完美分数,同时KV cache内存占用缩小了至少6倍。
PolarQuant单独使用,精度也几乎无损。
速度提升同样显著。
在英伟达H100 GPU上,4-bit TurboQuant计算注意力分数的速度,比32-bit未量化版本快了8倍。
不只是省内存,还更快了。
在向量搜索领域,TurboQuant同样超越了现有最优量化方法的召回率,而且不需要针对具体数据集做调优,也不依赖低效的大码本。
AI内存的DeepSeek时刻? Cloudflare CEO评价“这是谷歌的DeepSeek时刻”。
他认为DeepSeek证明了用更少的资源也能训出顶尖模型。
TurboQuant的方向类似,用更少的内存,也能跑同样质量的推理。
谷歌表示,TurboQuant除了可以用在Gemini等大模型上,同时还能大幅提升语义搜索的效率,让谷歌级别的万亿级向量索引查询更快、成本更低。
不过TurboQuant目前还只是一个实验室成果,尚未大规模部署。
更关键的是,它只解决推理阶段的内存问题。
而AI训练环节完全不受影响。
论文地址: https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/ 参考链接: [1]https://x.com/eastdakota/status/2036827179150168182?s=20 — 欢迎AI产品从业者共建 —
猜你喜欢
-
 万人火速入局!WPS笔记内测上线,支持龙虾直接“动笔” 热点 2026-03-25
万人火速入局!WPS笔记内测上线,支持龙虾直接“动笔” 热点 2026-03-25 -
 Claude能直接操控你的电脑微信了,这才是真正的上位小龙虾。 热点 2026-03-25
Claude能直接操控你的电脑微信了,这才是真正的上位小龙虾。 热点 2026-03-25 -
 全网都在“养龙虾”,高校为什么紧急叫停? 热点 2026-03-19
全网都在“养龙虾”,高校为什么紧急叫停? 热点 2026-03-19 -
 AI很火为啥不涨?盘盘GTC和关乎每个人“AI龙虾”的投资主线 热点 2026-03-19
AI很火为啥不涨?盘盘GTC和关乎每个人“AI龙虾”的投资主线 热点 2026-03-19 -
 小米深夜发布三大AI模型,国产AI再添硬核力量 热点 2026-03-19
小米深夜发布三大AI模型,国产AI再添硬核力量 热点 2026-03-19 -
 深入拆解 Agent 原理:LLM+工具+记忆+规划 科学原理 2026-04-14
深入拆解 Agent 原理:LLM+工具+记忆+规划 科学原理 2026-04-14 -
 人类历史上最绝望的推理 世间的一切早在138亿年前就已注定 世界之最 2026-04-07
人类历史上最绝望的推理 世间的一切早在138亿年前就已注定 世界之最 2026-04-07 -
 黑猫奇闻社雾城异事该怎么去推理雾城异事最终推理结论解析 奇闻百怪 2026-04-06
黑猫奇闻社雾城异事该怎么去推理雾城异事最终推理结论解析 奇闻百怪 2026-04-06 -
 立陶宛是一个什么样的国家,几十年后可能消失 热点 2026-04-22
立陶宛是一个什么样的国家,几十年后可能消失 热点 2026-04-22 -
 华为发布Pura X Max:首款大阔折形态折叠屏手机 热点 2026-04-20
华为发布Pura X Max:首款大阔折形态折叠屏手机 热点 2026-04-20 -
 华为发布Watch FIT 5小方表:27克超轻设计,1099元起售 热点 2026-04-20
华为发布Watch FIT 5小方表:27克超轻设计,1099元起售 热点 2026-04-20 -
 华为WATCH Buds 2发布:钛合金轻薄机身+3000尼特屏+全能健康监测 热点 2026-04-20
华为WATCH Buds 2发布:钛合金轻薄机身+3000尼特屏+全能健康监测 热点 2026-04-20
登录后畅享更多功能




