风控数据沉淀,风控数据模型不扎心
释疑解惑
2026-07-17
菜科探索
+

简介:风控数据沉淀,风控数据模型不扎心在开发模型的过程中,无论是针对传统的线性回归、逻辑回归模型,还是对于随
【菜科解读】
在开发模型的过程中,无论是针对传统的线性回归、逻辑回归模型,还是对于随机森林、GBDT、XGBoost等决策树模型,特征相关性分析是数据建模特征工程阶段一个必不可少的环节。
特征相关性分析及其变量筛选,可以有效优化模型的信息维度,并提升模型的区分能力,使模型在实际业务场景中保持较好的应用性能。
因此,特征的相关性分析是我们从事建模工作必须掌握的一项数据分析处理能力,做好这道处理工序也自然让流水化的作业稳稳的。
1、特征相关性分析
在分析样本特征变量的相关性时,针对不同取值类型的特征有不同的方法,主要分为以下几种情况:
(1)连续型与连续型:相关系数(pearson、spearman、kendall等)(2)连续型与离散型(二分类):T检验、Z检验(3)连续型与离散型(多分类):方差分析(4)离散型与离散型:卡方检验
在实际建模过程中,我们最常见的特征相关性分析情况是连续型与连续型之间,即采用perarson等相关系数来评价变量的相关程度,下面我们以具体样本数据来实现这个过程。
现有一份样本数据,包含5000条样本和16个特征,部分样例如图1所示,其中X01~X14为特征变量,Y为目标变量(取值二分类0/1)。
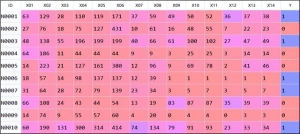
编辑
添加图片注释,不超过 140 字(可选)
图1 样本数据
针对以上样本的特征类型情况,我们通过python语言的corr()函数来实现变量的相关性分析,并指定系数类型method ='pearson',最终输出的二维矩阵系数结果如图2所示。
其中,对角线位置的数值表示变量本身的相关系数为1,其余数值为纵向变量与横向变量之间的相关性系数,例如变量X01与X02的pearson相关性系数大小为0.783652。
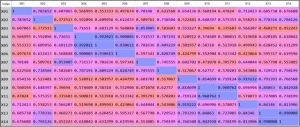
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图2 特征pearson系数
由上图分布结果,可以很直观的了解到变量之间的相关性情况,pearson系数绝对值越大,代表变量之间的相关性越强,正值代表正相关,负值代表负相关,pearson系数的取值范围为0~1。
从图中可见部分特征字段的相关性系数已经达到了0.9以上,如果将这些变量都保留下来进入模型拟合阶段,显然是不合理的,很有可能使模型存在较严重的共线性(线性回归、逻辑回归),或者导致模型在应用过程中容易出现较大波动等情形。
因此,对于相关性较强的变量,必须对其进行特征筛选,这是建模场景特征应用的要点,也是本文将要介绍的重点内容。
2、特征相关性筛选
在实际业务场景中,通过pearson系数来选取变量的过程,往往是通过某个阈值来进行保留和剔除。
一般情况下,当建模变量池的字段数量较多时,可以初步设置0.5作为筛选标准;
当建模变量池的字段数较少时,可以调整为0.6或0.7作为筛选标准。
因此,以0.5~0.7的某个阈值作为特征相关性选择标准最为常见,也符合信贷业务的建模需求与业务表现,具体数值也需要结合样本特征情况以及实际业务需求综合而定,但这是一个核心思路。
以图2的特征样例说明,变量X04与X05的相关性系数为0.992021,说明这两个字段的相关性很强,在某种角度理解,二者数据分布趋势基本一致,完全可以通过其中某一个字段来代替另一个字段,是不需要将其全部选入建模变量池中。
通常情况下,我们根据相关性系数分布,采用某个判断阈值例如0.7来进行特征选择,当系数大于0.7时会删除,但是当变量X04与X05之间相关性系数(0.992021)远大于0.7,虽然满足特征阈值的剔除条件,但注意不能全部将其删除。
针对这两个变量相关性程度较高的情况,我们在实际业务中往往会参考特征的其他指标来进一步分析确定最终需删除的变量,例如特征的缺失率miss、信息值IV等,现简要总结几种比较常用的实践处理方法:
(1)删除缺失率miss较高的变量;
(2)删除信息值IV较低的变量;
(3)删除稳定性PSI较大的变量;
(4)删除重要性importance较低的变量。
对于以上几种方式,方法1对模型的拟合效果不一定有效,有时特征的缺失分布情况也可以表现出较好的区分度;
而方法2~4虽然从贡献度(IV、importance)与稳定度(PSI)方面对变量池进行了合理选择,也有利于模型训练的拟合效果,但针对相关变量的指标计算也会消耗较多时间。
此外,还可以结合特征变量的其他维度指标来选取变量,例如共线性VIF、异常率outlier等,其应用逻辑与以上方法类似。
针对以上情况,本文要介绍的方法是仅针对特征相关性系数分布来展开变量筛选,也就是对于相关性系数较大的两个特征,不借助其他维度指标来进行变量删除,而是要结合当前两个特征与其他特征的相关性程度,具体实现过程如下:
(1)获取所有特征变量的相关系数矩阵;
(2)选择相关系数值最大的变量组合(例如X1与X2);
(3)算出变量X1、X2与其他所有变量{Xn}相关性系数的平均值w1、w2;
(4)比较平均相关性系数w1、w2的大小关系;
(5)当w1>w2删除X1,当w1<w2删除X2,当w1=w2删除X1或X2均可;
(6)重复步骤2~4,直到变量相关系数最大值低于预设阈值(常见0.5~0.7)。
以图2分布结果的变量组合X04与X05为例,由于二者相关性系数(0.992021)很高,需要删除其中之一。
X04与X05与其他变量之间的相关系数及其平均值结果具体如图3所示。
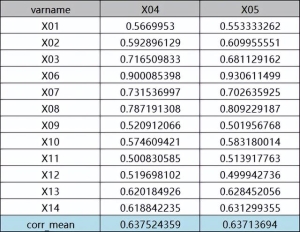
编辑
添加图片注释,不超过 140 字(可选)
图3 特征X04与X05相关系数
从结果可知,X04与X05与其他变量的平均相关性系数分别为0.637524359、0.63713694,由于前者大于后者,说明X04相比X05在所有变量中的相关性较强,因此可以将变量X04删除。
这样在剩余的13个特征变量中,仍然选取相关性系数较高的变量组合,然后采用以上平均相关性系数分析的方法,依次实现变量的相关性筛选,直到满足剩余变量的最大相关性系数小于阈值即可。
为了自动化完成以上特征筛选过程,可以通过图4代码实现批量特征分析与处理,由于本文实例样本数据的特征相关性系数普遍较高,我们以0.8为最终相关性判断阈值。
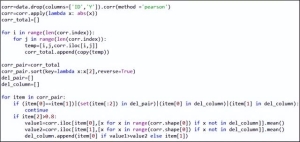
编辑
添加图片注释,不超过 140 字(可选)
图4 特征相关性筛选过程
在生成的数据del_column中,字段Value便是根据特征相关性分析需要删除的变量,具体结果如图5所示,但Value的取值并非特征变量名称,而是特征X变量对应的列索引,也就是数字0~13依次表示变量X01~X14。
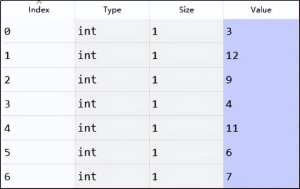
编辑
添加图片注释,不超过 140 字(可选)
图5 特征相关性删除变量
为了便于对待删除变量的分析与处理,我们将其列索引转换为变量名称,实现过程如图6所示,根据变量相关性筛选阈值0.8,最终需要删除的变量为X04、X13、X10、X05、X12、X07、X08共7个变量。
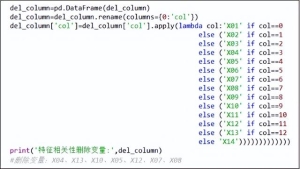
编辑
添加图片注释,不超过 140 字(可选)
图6 样本待删除变量汇总
当然,在实际业务场景中,还可以根据特征变量与X与目标变量Y的关系,得到每个特征的信息值IV,可以对特征变量进一步筛选,从而有效保证模型变量拟合训练的综合效果,即使模型具有较好的区分度和稳定性,这也是特征相关性筛选最终需要实现的目标。
以上内容便是围绕特征相关性分析来完成特征变量筛选的介绍,这在数据建模中特征工程的数据分析环节是非常重要的,在具体实际场景中可以与特征共线性、特征重要性等其他特征处理方式相结合,以获取一个综合性能较优的模型。
为了便于大家理解本文特征相关性分析及其筛选的相关内容,本文额外附带了与实例分析同步的样本数据与python代码,详情请移至知识星球查看相关内容。
猜你喜欢























登录后畅享更多功能




