sli显卡性能会提升多少不用新桥性能受损
显卡
2026-07-11
菜科探索
+

简介:在显卡行业里,有这么一个品牌,它乐于埋头钻研先进的技术,时不时拿出令人惊诧的设计,但平时却疏于宣传造势
【菜科解读】
在显卡行业里,有这么一个品牌,它乐于埋头钻研先进的技术,时不时拿出令人惊诧的设计,但平时却疏于宣传造势,以至于许多人常常忘记了它的存在。
在小编心中,它是一个“无声的王者”——技嘉显卡。

技嘉显卡是为数不多的,真正用心设计产品的品牌,相比一些循规蹈矩的庸碌之辈,它总是能令人耳目一新,从同质化竞争中脱颖而出。
小编本文要向大家深度分享的是技嘉显卡最新推出的旗舰型号GTX 1080 XTREME GAMING,它身上的多处亮点能赋予用户与众不同的体验。
小编总结出以下三点:

融汇多项先进设计的风之力3X散热系统
技嘉显卡的散热系统“风之力”一向是其引以为豪的招牌,仔细研究就会发现它蕴含了许多独到的设计思路,并且一直不断地推陈出新。
这款GTX 1080 Extreme GAMING显卡上“风之力”已经升级到第三代。

VR用户的超级福音,独一无二的前置HDMI设计
帕斯卡这一代显卡为VR做了许多优化,但VR头盔毕竟不能完全代替显示器,也不适合一直连接在电脑上,于是技嘉这款GTX 1080为此做了进一步优化,便于插拔的前置HDMI堪称独具匠心。

提供符合NVIDIA新规范的SLI桥接器,多重RGB信仰灯加持
NVIDIA在帕斯卡首发时宣布这一代产品组SLI时需要新版本的桥接器,否则性能可能受损。
技嘉GTX 1080 XTREME GAMING豪华套装随盒附赠了一个带有“XTREME GAMING”发光Logo的新版桥。
这是小编自GTX 1080发布之后得到的第一个新桥,借此机会在这篇评测中还将为大家测试分析新桥与旧桥之间的区别,是否真如NVIDIA所述那样。
技嘉GTX 1080 XTREME GAMING大图鉴赏
先上几张大图欣赏,再为大家掰开了揉碎了讲解技嘉GTX 1080 XTREME GAMING

正面
这款GTX 1080的厚度是超出双槽的,虽说还不至于影响组SLI,但可能遮挡住下方紧邻的某个PCIE/PCI插槽,这是小编唯一对它不满的地方。
不过,考虑到该产品中存在那么多“走心”的设计,倒也是能忍。

正面
虽说这是技嘉显卡目前最顶级的产品,灯饰设计却不乖张,除了侧脊上的“XTREME GAMING”信仰灯之外,就是在中央风扇框加了个“X”形灯条,以彰显它的XTREME属性。
这些灯都可以接受技嘉APP控制改变颜色。

正面
得益于风之力3X散热系统的逆天设计,安装了三枚10cm直径风扇的显卡依然能将长度控制在一个理想的范围内,它是如何实现的?接下来的散热器介绍部分再为大家仔细剖析。

背面,这个档次的显卡,铝合金背板是少不了的

视讯输出端口
挡板上显示端口的配置依然是3DP 1HDMI 1DVI,再加上用于前置的额外两个HDMI接口,技嘉这款GTX 1080成为接口最多的显卡。
重峦式风扇,闻所未闻
看得出来,相比其它大多数品牌,技嘉在散热设计上付出的心血要多得多。
这次风之力3X散热系统向我们展示了史无前例的奇妙结构。

风之力3X散热系统工作示意图
中间的风扇有双层扇叶,上层扇叶直径很小,刚好嵌入左右两个风扇之间,下层扇叶直径则与左右风扇相同,为10cm。
这种重峦式结构使不到30cm长的显卡可以容纳三枚10cm直径的大尺寸风扇。
关于大风扇的好处,大家都懂,这里就不再累述了。

中间的风扇下沉

中间风扇与两旁的扇叶重叠

重峦式扇叶结构
这种叠加的风扇结构除了压缩空间,还显著提升单位面积内的风力,使风扇覆盖的散热片得到均衡的气流通过,对它做更加充分的利用。

双滚珠轴承
寿命最长的双滚珠轴承,成本也几乎是最高,这也是技嘉风之力3X散热系统的一个重要升级。
显卡在长年累月地使用之后,一旦风扇轴承损坏,会发出恼人的噪音,甚至会无法转动,这时候因为产品停产,往往很难找到维修备件,所以让最好的解决办法就是让风扇的寿命延长到与显卡本身平齐。
这散热片设计也是呕心沥血了
小编从未见过有哪个品牌像技嘉这样在散热器的气动外形上下这么多功夫,看似平白无奇的鳍片中隐含着设计者的讲究。
要说不这么讲究显卡用着也没啥问题,但百尺竿头更进一步,高手之间差距就是这么一点。

技嘉GTX 1080 XTREME GAMING的散热器本体

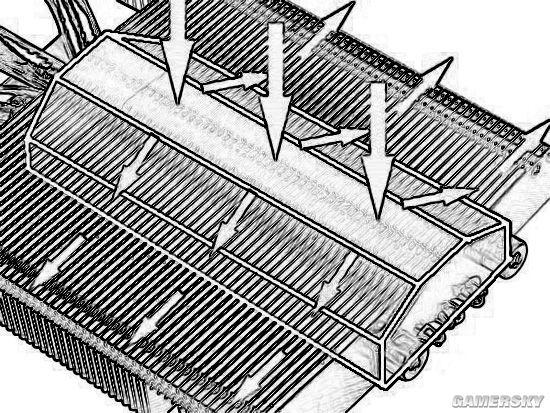
风之力3X散热系统中加入弯月式鳍片设计,气流阻力降到最低
常见的散热器鳍片都是直上直下地排列,技嘉这个却要拐个弯,理由很简单,风扇产生的气流并非垂直作用在鳍片阵列上,是有倾斜角度的。
弯月式鳍片与普通鳍片对比效果图
顺着气流运动的轨迹,令其平滑地改到垂直,每相邻的两个鳍片之间都形成一个整流风道,这样防止气流反弹,使吹透鳍片所需的风压更低。
换句话说,就是降低空气流经鳍片的阻力,提高流速和流量,因此而获得的散热效果提升就不言而喻了。

技嘉风之力散热系统的经典设计:梯形导流片
此外,前几代风之力散热器上经典的梯形导流设计得到了保留,无疑是锦上添花。
风之力导流片效果图
鳍片与鳍片之间夹着一个梯形的铝板,用两根强力螺丝将它们紧固在一起。
梯形铝片的斜边能将风扇气流从与鳍片垂直,扰流成顺向着鳍片向两侧运动。
这样一来气流便可以充分流经表面鳍片表面,达到最佳换热的目的。
为VR而生,首创前置HDMI端口
VR头盔的使用情形与耳麦有些类似,用到它的时候才会插上,所以若有便于插拔的前置端口是再好不过了。
本来这个设想有赖于显卡与机箱设计的共同进步,技嘉却提前为大家实现了。

前置HDMI USB3.0二合一面板,适装光驱位
还记得GTX 1080 XTREME GAMING安装在PCB另一边的两个HDMI接口吗?它就是干这个用的,从机箱内走线,丝毫不影响美观。
或许是因为偌大的面板只有2个HDMI太浪费空间了,技嘉还在上面设计了一对USB3.0接口,可连接到主板上的插针。

显卡另一侧额外的HDMI端口

连接HDMI延长线
通过延长线和光驱位的面板,可以将视讯信号输出到机箱前端,即插即用。

HDMI机箱后挡板适配组件
若不想用前面板,用户还有另一种选择,将前面板拆掉换成机箱后挡板,这便为显卡增加了两个额外的HDMI接口,也算物尽其用。
需要注意的是,这些外部零件均为选配,只有在GTX 1080 XTREME GAMING的豪华套装里才随盒附赠,即“Premium Pack”,普通包装是没有的。
做工用料?技嘉水准安心洗路
说到PCB电路板的质量,技嘉无论是主板还是显卡,从来都是毋庸置疑的。
GTX 1080 XTRME GAMING采用时下最流行的加高设计,控制长度的同时能容纳更高规格的元器件,表面附有绝缘镀层,可防水溅洒短路。

技嘉GTX 1080 XTREME GAMING的PCB裸板

其中两个DP端口通过桥接芯片将视讯信号转接到另一边的两个HDMI端口上

论堆料,技嘉从未掉出过第一梯队
供电系统技嘉采用低损耗,内置驱动器的DrMOS功率IC,组成6相12回路的庞大供电线路,并在低压滤波端毫不吝啬地全面采用钽聚合物电容,可以说这已远远超出GP104芯片的设计需求。
以至于该显卡在极限负荷下无论多么长时间地工作,都不会有丝毫的稳定性隐患。

显存容量共8GB,采用镁光黑科技的DDR5X颗粒,GTX 1080的标配
对技嘉GTX 1080 XTREME GAMING的介绍到此告一段落,相信读者已经领略了技嘉显卡的种种过人设定,它们是否能切实有效地发挥作用?是骡子是马还得拉出来溜,下面进入上机测试环节。
测试平台软硬件介绍
除了基准测试和散热测试之外,小编准备了六款最近一年发售的单机游戏大作来反映技嘉GTX 1080 XTREME GAMING的性能。
另外,小编趁手里刚好有两片这款显卡的机会,还将为大家测试解疑新SLI桥接器的问题。

测试平台特写
游戏测试将涵盖1920×1080、2560×1440以及3840×2160三种分辨率,游戏画质选项全开最高,视情况开启合适的抗锯齿。
测试平台软硬件配置列表:
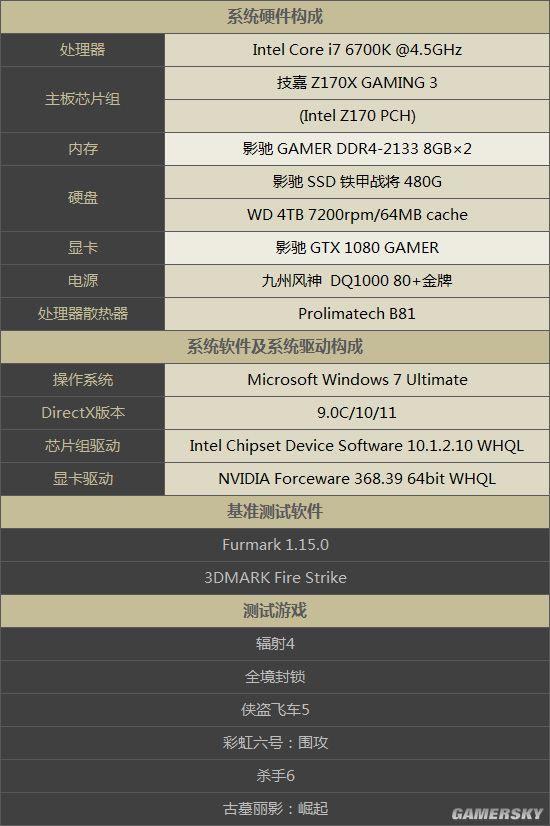
本次测试涉及当今性能最强的单核心显卡,及其双路SLI,为了充分发挥性能,尽可能消除系统瓶颈,测试中将处理器Core i7 6700K设置在4.5GHz频率下,内存运行在DDR4-2400,该设定符合大多数硬件发烧友的使用习惯。

测试平台使用技嘉Z170X GAMING3主板
Z170X GAMING3是技嘉GAMING系列的当家花旦,功能齐备的同时价格适中。
它拥有速率高达16Gbps的Intel原生主控USB3.1接口,其中一个接口支持Type-C;
拥有32Gbps的PCI-E3.0 4×通道支持的两个M.2接口;
享有包含Realtek旗舰级板载音频芯片和高品质音频专用电容的音效系统设计;
它最多能支持3路多卡互联,采用加强型PCI-E16×插槽。
总而言之,该主板是追求品质的高端游戏玩家。
基准性能测试:默频得分过万
首先基准测试,在运行3DMARK之前,先看一下技嘉这款显卡的频率设置,下面直接给到GPU-Z截图,一目了然。
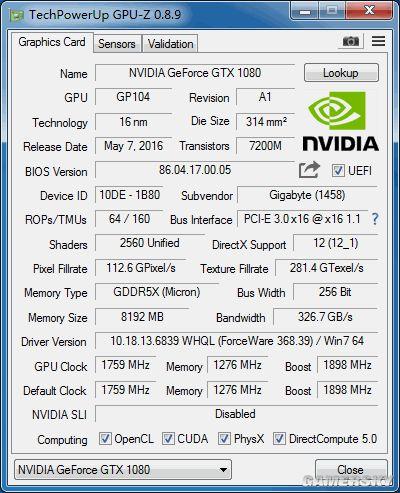
技嘉GTX 1080 XTREME GAMING的GPU-Z截图
该显卡的默认频率设置远超NVIDIA公版标准,核心基础频率为1759MHz,Boost高达1898MHz,就连显存等效频率也超过公版200MHz。
这还远远不是终点,通过技嘉最新开发的APP——XTREME ENGINE,玩家可以利用它强大的超频功能尝试更高频率。
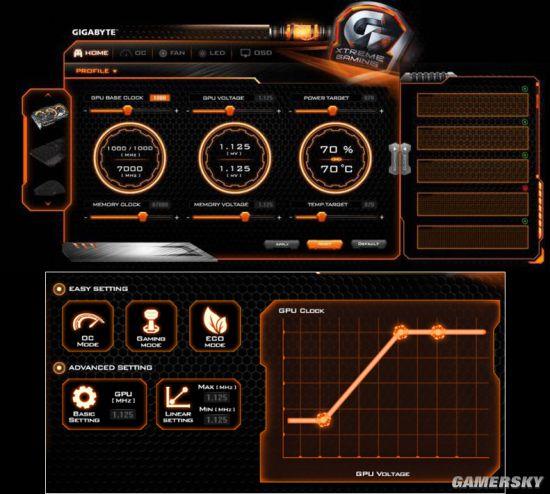
通过技嘉官方APP,除了手动超频还有三种预设模式可选
这款APP的设计十分贴心,如果觉得一点点尝试手动超频很麻烦,不妨直接使用预设模式,有三种可选,分别是OC、GAMING、ECO。
顾名思义,OC模式频率最高,核心Boost设置到了1936MHz;
GAMING是游戏模式,即显卡的模式设置;
ECO是经济模式,频率低于默认设置,同时发热也会减少,风扇会在更多的时间里停止工作。
为了测试技嘉GTX 1080 XTREME GAMING显卡在平常状态下,以下所有测试测试均使用GAMING模式(不安装APP也是这个频率)。
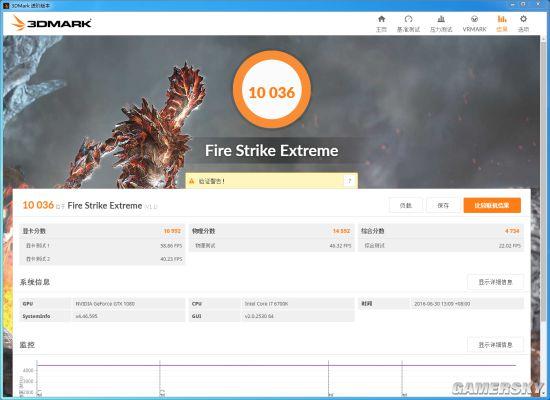
3DMARK Fire Strike Extreme得分10036
参考价值最为广泛的Fire Strike Extreme,技嘉该卡默认频率既能得分破万,GTX 1080的万分俱乐部又多一成员。
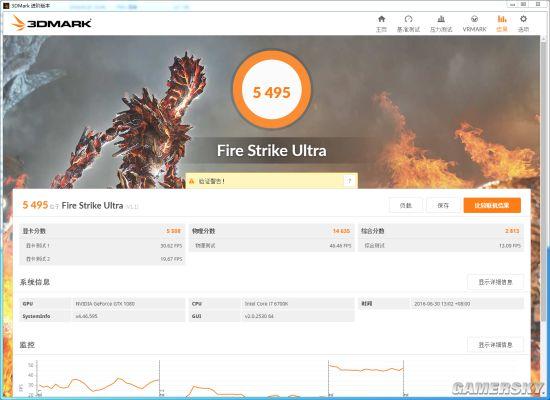
3DMARK Fire Strike Ultra得分5495
在4K专用测试Fire Strike Ultra中5000分是一个分水岭,超过这个分数代表显卡拥有在4K下流畅运行单机游戏大作的能力,技嘉这款GTX 1080显然具备。
散热噪音测试:零噪音
对老黄的死忠粉来说,买泰坦皮是义不容辞,遗憾的是它不能满足对静音要求高的人,比如小编这样的。
公版在待机状态下风扇也会孜孜不倦地转,过千的转速将GPU温度压到跟常温差不多,然而这并没有什么软用。
待机散热效果与公版GTX 1080对比
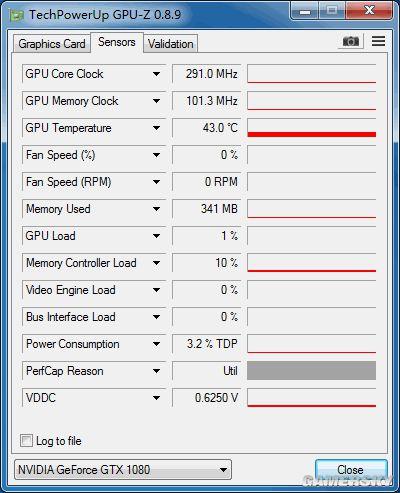
技嘉GTX 1080 XTREME GAMING待机温度43℃,风扇不转,零噪音
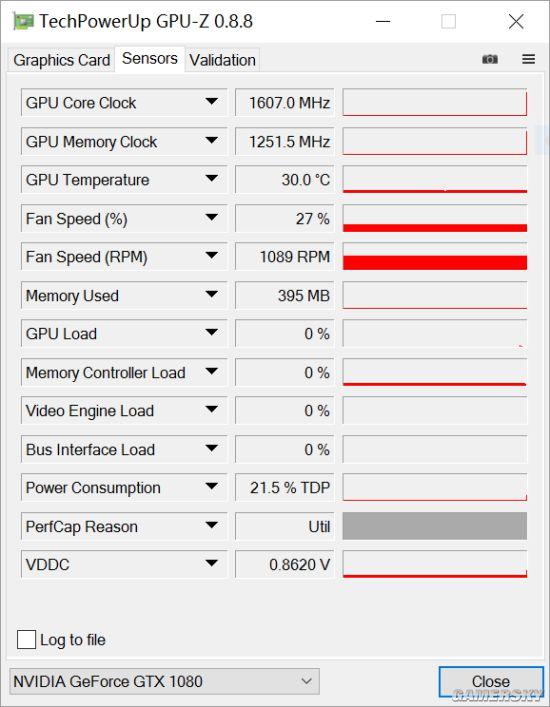
NVIDIA公版GTX 1080待机30℃,但风扇有噪音
可见技嘉风之力的被动散热效果是相当不错的,风扇全部停止状态下GPU温度牢牢稳定在43℃,截止小编截图之前的半个小时内风扇没有启动过一次。

风扇启停指示灯
有待机零噪音设计的显卡品牌不少,有启停指示灯设计的却只有技嘉一个。
三个风扇全都停止时该灯会亮起,提醒你显卡处于被动散热状态,反之则熄灭。
这是个非常贴心的设计,显卡高负载时你不用总是为风扇是否启动而疑神疑鬼,真是为不少用户疏通了的心理障碍。
满载散热效果与公版GTX 1080对比
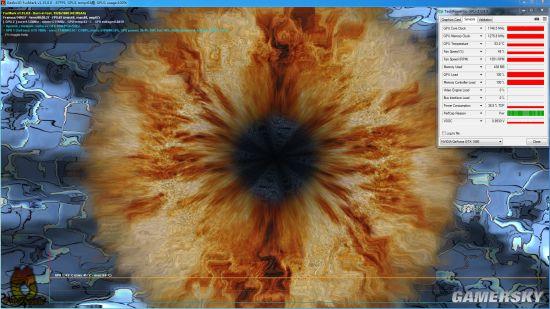
技嘉GTX 1080 XTREME GAMING甜甜圈测试63℃

NVIDIA 公版GTX 1080甜甜圈测试81℃
满载测试差别就更大了,技嘉GTX 1080比公版低了18℃,并且前者还是运行在更高的的Boost频率上。
相比公版飙升到2000rpm以上的风扇,技嘉风之力只有1500rpm左右,噪音控制的非常出色,几乎也听不见声音。
看来新一代风之力散热系统的多项新颖设计卓有成效,小编相信即使室内不开空调,它也能助你安度这个三伏天。
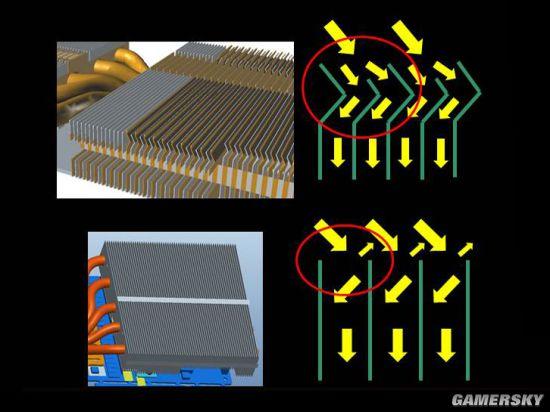
是时候进入SLI的话题了,前面小编提到探讨新桥与旧桥可能有差别的问题,稍安勿躁,咱们先用新桥对双路GTX 1080 XTREME GAMING的性能进行一次摸底。
从以上得分来看,GTX 1080双路SLI的性能提升幅度与上一代显卡没有明显区别,分辨率和计算负载越高,提升幅度越大。
看来即便CPU超频到4.5GHz,在Extreme测试里还是略有瓶颈的。
单卡与双路SLI游戏性能对比
然而在个别游戏实测中,GTX 1080的双路SLI出现了奇怪的现象:1080P和2K分辨率下双卡帧数反倒不如单卡,如《GTA5》、《彩虹六号:围攻》。
回顾之前的测试,排除游戏本身对SLI的支持问题之后,小编判断这很可能是驱动程序支持帕斯卡架构还不够完善所致。
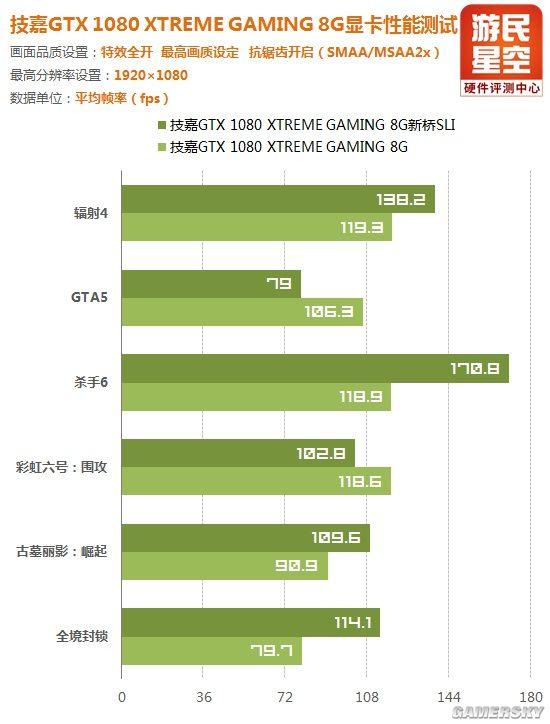
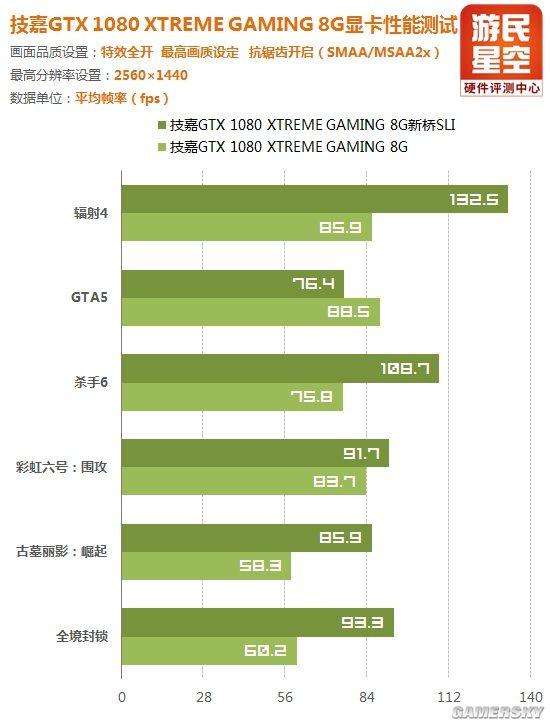
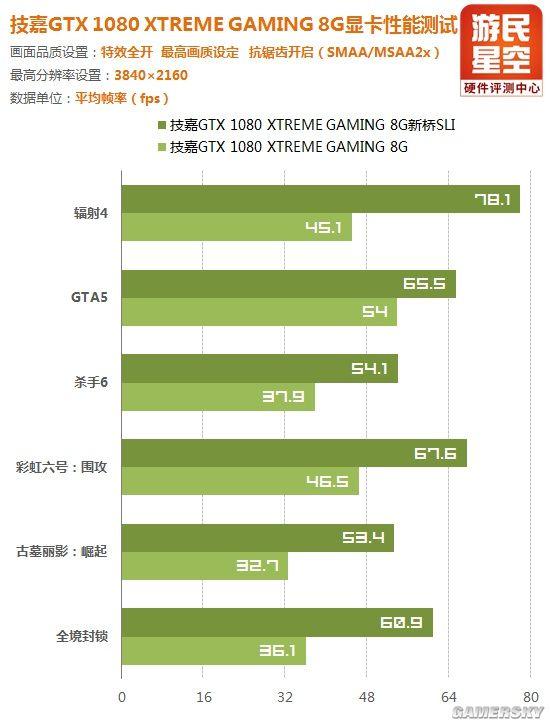
不过分辨率提高到4K之后,这两款游戏的SLI性能逻辑又回归正常,只是相比单卡提升幅度不是很大。
其它游戏性能表现基本正常,总之,这是需要NVIDIA去解决的问题。
NVIDIA含糊不清的锅,新SLI是咋回事?
NVIDIA在发布GTX 1080时留下了一个令人困惑的问题,小编借这次机会要为大家研究个水落石出。
NVIDIA宣称新一代显卡的SLI桥接设计有变化,需要用新桥才能充分发挥性能,若用之前的老桥性能会有损失。
可是经过仔细对比,发现GTX 1080的SLI金手指相比以前没有任何变化。
SLI桥里并无复杂的电路,只是起到简单的“针对针”连通作用,新桥和老桥的区别又在哪里呢?

上为技嘉GTX 1080,下为其它品牌的GTX 980 Ti
非要说区别,也不是完全没有。
新的双路SLI桥一次性将两个端口全都连接上了,我们知道之前的显卡组双路SLI时只需要连接其中一个端口,只有在组两路以上时才需要用到第二个端口。

技嘉GTX 1080 XTREME GAMING随盒提供的新款SLI桥
若新和旧的差别仅此而已,就意味着以前的SLI桥还是可以用的,只不过需要把两个接口都连上,像下图那样。

小编之前用了很久的桥,该桥自SLI诞生一直没变,两个端口都连上试试
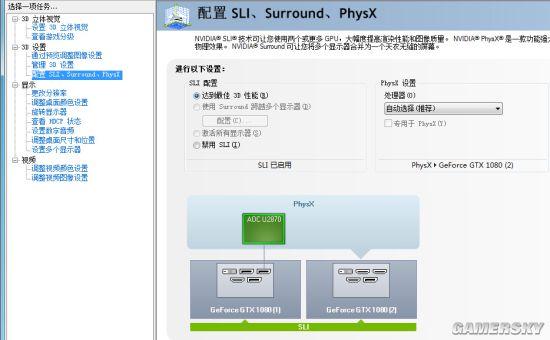
驱动程序界面都显示SLI工作正常
结果显示,无论用新桥,还是用两个旧桥一起连上,都能成功组建GTX 1080双路SLI,未发现任何异常。
下面再试试只连接其中一个,就像用帕斯卡以前的显卡组双路SLI那样。

效仿以前组双路SLI那样只接一个桥试试
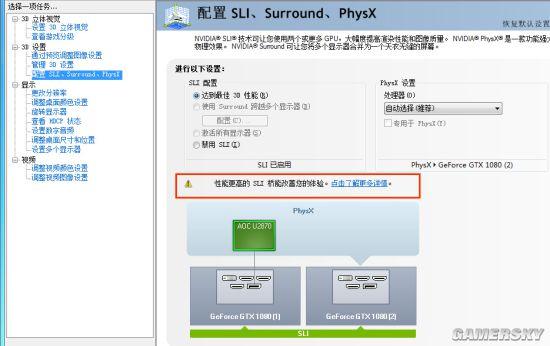
驱动里果然有反应了
通过这一阶段的尝试可以判断,用GTX 1080组双路SLI,新桥和旧桥(只连接单个端口)的确是有区别的,驱动会提示你还可以用性能更高的SLI桥,不过单桥状态下SLI依然可以正常工作,只是性能如何就不得而知了。
最终测试马上开始!
三种SLI桥接测试对比,真相水落石出
最后,小编将通过一套详细的游戏测试,为大家解开GTX 1080双路SLI桥的谜团。
下面为六款单机游戏大作在三种分辨率下的SLI测试成绩,桥接状态分别为技嘉提供的新桥、旧桥双连、旧桥单连。
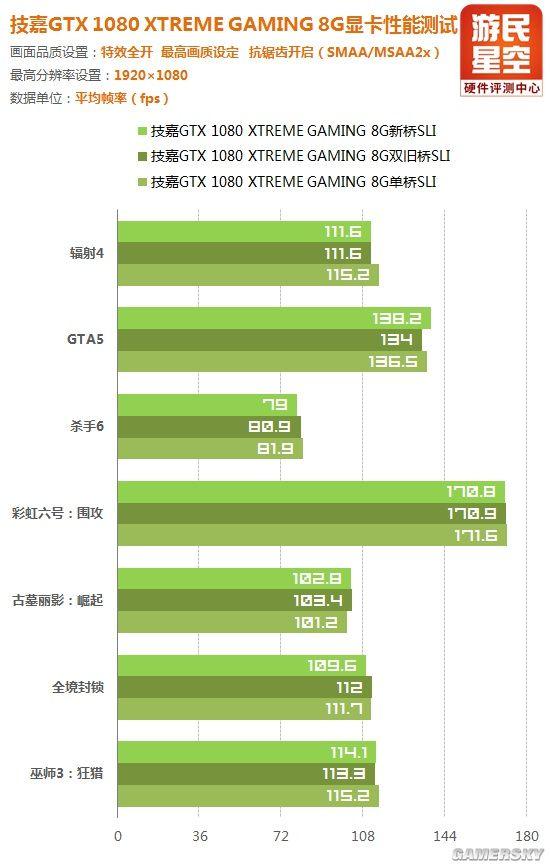
1080P分辨率下,三种桥接方式的游戏帧数没有任何区别。
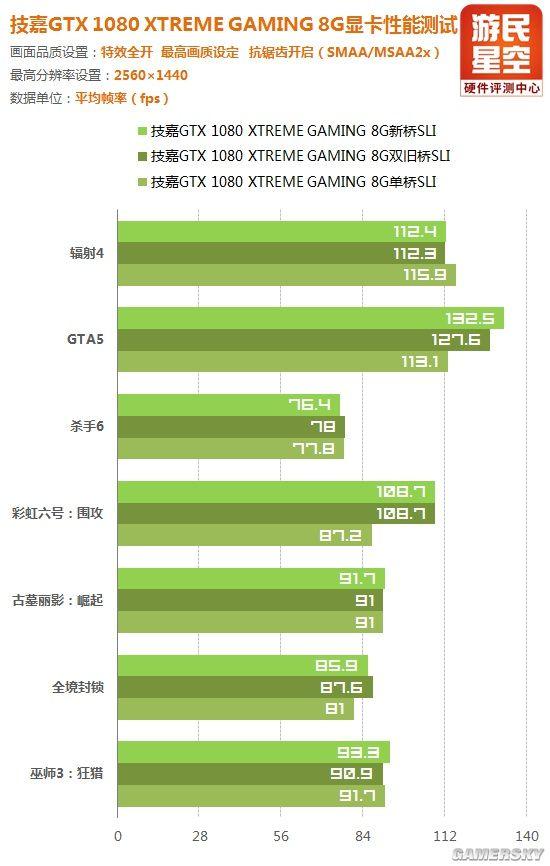
2K分辨率下,单桥状态在个别游戏中出现明显的性能损失,超出成绩波动范围。
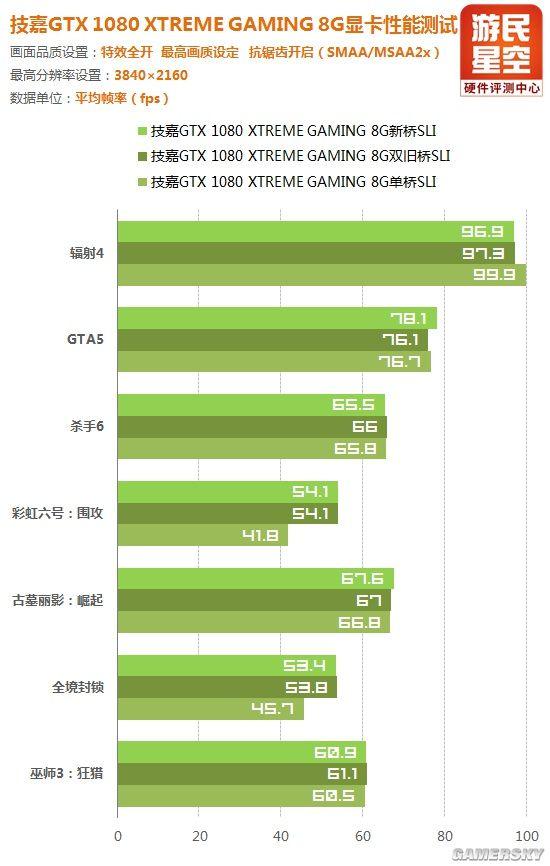
4K分辨率下,单桥状态个别游戏的性能损失更加明显,而新桥和双旧桥仍然是一样的。
由此可以断定,GTX 1080显卡确实需要新桥来确保双路SLI的性能100%充分发挥,尽管目前出现差别的现象还不是那么普遍。
或许GTX 1080的SLI互联需求只是刚刚突破了单桥的传输上限,等未来NVIDIA更高端的显卡出现便能说明问题。
至于新桥与旧桥的关系,就单个端口而言,小编认为它们是完全相同的,前者只不过是做成了后者的double。
所以今后组双路SLI时并不一定要去找新桥,用两个单桥全都连上也是一样的。

技嘉GTX 1080 XTREME GAMING售价5699元














登录后畅享更多功能




